What is Transfer Learning?
Transfer learning is a machine-learning technique where knowledge learned from one task is reused for a related task. Instead of training a model from scratch, we start from a model that has already learned useful patterns from a large dataset and adapt it to a new problem.
This is especially helpful when the new task has limited labelled data. A model trained on a broad image dataset, for example, may already understand edges, textures, shapes, and object parts. Those learned features can be reused for medical images, defect detection, remote sensing, or digit classification with much less training data.
large source task -> pre-trained model -> adapted target task
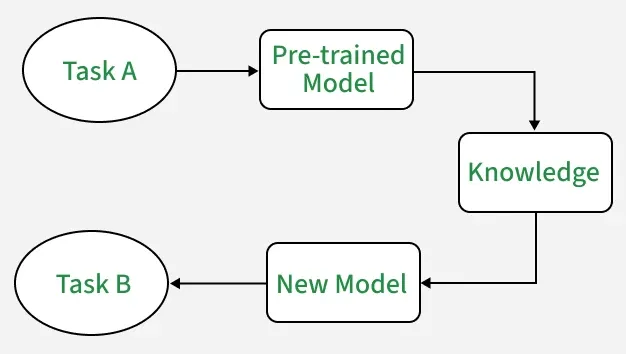
Why Transfer Learning Matters
Training a deep model from zero can be expensive because it usually needs a large dataset, strong hardware, and long training time. Transfer learning reduces that burden by reusing a model that already has general-purpose representations.
Important advantages:
- Less data required: The target task can benefit from features learned on a larger source task.
- Faster training: Fewer parameters may need to be trained from scratch.
- Better starting point: Pre-trained weights often produce better early performance than random initialization.
- Improved generalization: General features learned from broad datasets can reduce overfitting on small target datasets.
- Lower cost: Reusing existing models can save computation, time, and development effort.
How Transfer Learning Works
Most transfer-learning workflows follow four steps:
- Choose a pre-trained model. Start with a model trained on a large source dataset, such as ImageNet for vision or a large text corpus for natural language processing.
- Reuse the base model. Keep the early and middle layers that already learned reusable representations.
- Replace the task-specific head. Remove or replace the final classifier or prediction layer so the model matches the new target labels.
- Train or fine-tune. Train the new head first, then optionally unfreeze some deeper layers to adapt the model more closely to the target data.
For image models, early layers often learn generic features such as edges and textures. Deeper layers learn more task-specific patterns such as object parts or class-level concepts.
Frozen and Trainable Layers
A central design choice in transfer learning is deciding which layers should stay frozen and which layers should be updated.
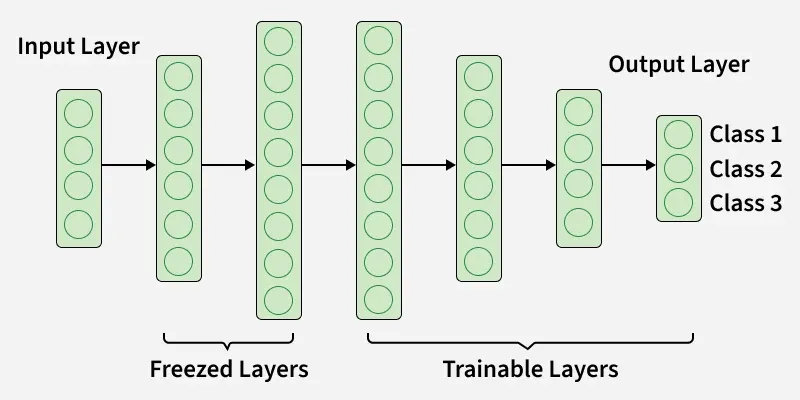
| Aspect | Frozen Layers | Trainable Layers |
|---|---|---|
| Meaning | Weights are kept fixed during training. | Weights are updated during training. |
| Purpose | Preserve general knowledge from the source task. | Adapt the model to the target task. |
| Computation | Lower training cost because fewer parameters change. | Higher cost because more parameters are optimized. |
| Typical use | Small or similar target datasets. | Larger or different target datasets. |
| CNN example | Early convolution layers that detect edges and textures. | Later convolution or dense layers that learn task-specific patterns. |
Choosing What to Freeze
The decision depends mainly on dataset size and similarity between the source and target domains.
Small and Similar Dataset
Freeze most of the base model and train only the new output head. This limits overfitting and keeps the general features intact.
Example: adapting an ImageNet model to classify a small set of everyday object categories.
Large and Similar Dataset
Unfreeze more layers and fine-tune part of the model. Because there is enough data, the model can adapt without immediately overfitting.
Example: adapting a general image classifier to a large industrial image dataset.
Small and Different Dataset
Be careful. The pre-trained features may not fully match the new domain, but the target dataset may be too small for full training. A common strategy is to freeze early layers, train the new head, then fine-tune only a small number of later layers with a low learning rate.
Example: adapting a natural-image model to a small medical-imaging dataset.
Large and Different Dataset
Fine-tune more of the model, or even the whole model, because the target data is large enough to support deeper adaptation.
Example: adapting a general visual backbone to satellite imagery or specialized scientific images.
Common Workflow
A simple deep-learning workflow looks like this:
load pre-trained backbone
remove original classifier
add new classifier for target labels
freeze backbone
train new classifier
unfreeze selected layers
fine-tune with a small learning rate
evaluate on target test data
In Keras, a typical transfer-learning pattern is:
from tensorflow.keras.applications import MobileNetV2
from tensorflow.keras.layers import Dense, GlobalAveragePooling2D, Input
from tensorflow.keras.models import Model
base_model = MobileNetV2(
weights="imagenet",
include_top=False,
input_shape=(224, 224, 3),
)
base_model.trainable = False
inputs = Input(shape=(224, 224, 3))
x = base_model(inputs, training=False)
x = GlobalAveragePooling2D()(x)
outputs = Dense(num_classes, activation="softmax")(x)
model = Model(inputs, outputs)
After the new classifier learns a useful mapping, selected layers can be unfrozen:
base_model.trainable = True
for layer in base_model.layers[:-20]:
layer.trainable = False
model.compile(
optimizer=tf.keras.optimizers.Adam(learning_rate=1e-5),
loss="categorical_crossentropy",
metrics=["accuracy"],
)
The smaller learning rate matters because fine-tuning should adjust the pre-trained features gently rather than overwrite them.
Applications
Transfer learning is widely used across modern AI:
- Computer vision: Image classification, object detection, facial recognition, medical-image analysis, remote sensing, and quality inspection.
- Natural language processing: Text classification, sentiment analysis, question answering, summarization, and information extraction using pre-trained language models.
- Healthcare: Diagnostic support from X-rays, MRI, CT, pathology slides, and other data-scarce medical datasets.
- Finance: Fraud detection, credit scoring, risk prediction, and anomaly detection where patterns learned from one dataset can support related tasks.
- Wireless communications: Beam selection, localization, channel estimation, and resource allocation when a model trained in one environment is adapted to another deployment scenario.
Advantages
- Training is faster because the model starts with useful representations.
- Performance can improve when the target dataset is small.
- Data requirements are lower than full training from scratch.
- Compute cost can drop because only part of the model may need training.
- Deployment is easier when well-tested pre-trained backbones are available.
Limitations
Transfer learning is powerful, but it is not automatic magic.
- Domain mismatch: If source and target data are too different, transferred features may be weak or misleading.
- Negative transfer: Reusing unsuitable knowledge can reduce performance.
- Overfitting: Fine-tuning too many parameters on a small dataset can harm generalization.
- Hardware demand: Large pre-trained models may still require significant memory and compute.
- Bias transfer: A model can carry biases from the source dataset into the target application.
Practical Tips
- Start with a frozen backbone and train the new classifier first.
- Use a smaller learning rate during fine-tuning.
- Unfreeze gradually instead of training every layer immediately.
- Use validation performance to decide how many layers to unfreeze.
- Keep data preprocessing consistent with the pre-trained model.
- Compare against a simple baseline so transfer learning is actually earning its keep.
Summary
Transfer learning reuses knowledge from a source task to improve learning on a target task. It is especially useful when labelled data is limited or training from scratch is too expensive. The key practical decision is how much of the pre-trained model to freeze, how much to fine-tune, and whether the source and target domains are similar enough for transfer to help.
References
- GeeksforGeeks, "Introduction To Transfer Learning", last updated May 9, 2026.
- K. He, X. Zhang, S. Ren, and J. Sun, "Deep Residual Learning for Image Recognition", CVPR, 2016.
- J. Deng et al., "ImageNet: A large-scale hierarchical image database", CVPR, 2009.
- S. J. Pan and Q. Yang, "A Survey on Transfer Learning", IEEE Transactions on Knowledge and Data Engineering, 2010.